IA é reprovada em teste básico de atenção
Redação do Diário da Saúde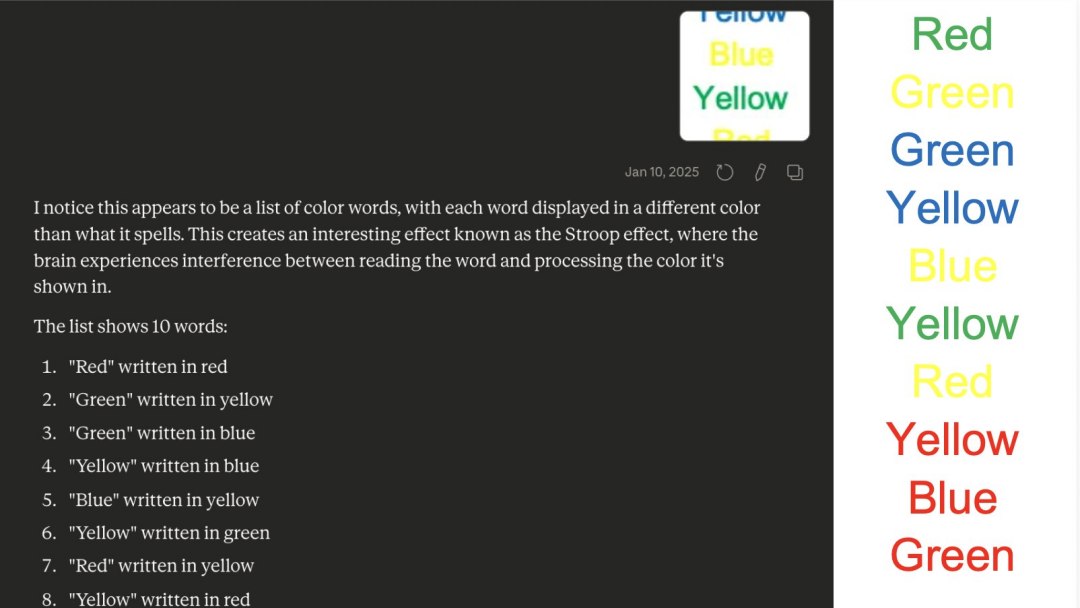
[Imagem: Suketu Chandrakant Patel et al. - 10.1093/pnasnexus/pgag149]
Preste atenção na cor
Os grandes modelos de linguagem (LLMs), a tecnologia por trás da inteligência artificial generativa, como Gemini, DeepSeek, ChatGPT e tantos outros, foram reprovados em um teste psicológico clássico, conhecido como tarefa de Stroop.
O teste consiste em pedir que uma pessoa diga as cores nas quais uma lista de palavras está escrita; o detalhe é que as palavras são nomes de cores, o que significa que a pessoa deve nomear as cores ignorando o significado da palavra.
Essa tarefa é usada clinicamente para avaliar o controle executivo, especialmente a capacidade de uma pessoa de inibir uma resposta automática (ler a palavra) em favor de uma resposta controlada (nomear a cor da tinta). Os humanos geralmente demoram mais para responder corretamente quando palavras e cores não coincidem do que quando coincidem, mas se saem bem de forma estável e com alta precisão mesmo em listas longas, suprimindo a leitura da palavra e mantendo o foco na identificação da cor.
Não foi bem o que aconteceu com os aplicativos de inteligência artificial, que se complicaram rapidamente.
E os resultados levantam questões importantes sobre até que ponto os aplicativos de IA realmente "compreendem" instruções e sobre quais aspectos da cognição humana permanecem fora do alcance desses modelos.
Atenção biológica e atenção de IA
Diferentemente dos humanos, os aplicativos de IA apresentaram um colapso dramático de desempenho à medida que a lista de palavras crescia.
O ChatGPT-4o, por exemplo, caiu de 91% de acerto em uma lista com cinco palavras para 57% com dez palavras e apenas 15% com quarenta palavras. O Claude 3.5 se manteve estável até vinte palavras, mas despencou para 24% de acertos com quarenta palavras.
Quando a lista continha uma mistura de palavras congruentes e incongruentes (cores que correspondiam ou não ao significado), o desempenho dos aplicativos de IA foi ainda pior, chegando a quase 0% nos itens incongruentes.
Suketu Patel e colegas da Universidade Cidade de Nova York (EUA) atribuem o fracasso da IA nessa tarefa de atenção ao fato de que os modelos de linguagem são mais bem treinados na leitura de palavras do que na nomeação de cores. Os humanos também são, mas os modelos de IA não conseguem sustentar a supressão da resposta automática ao longo de listas longas - eles perdem o foco, por assim dizer.
O colapso de desempenho sugere limitações fundamentais da atenção dos LLMs em comparação com a atenção biológica, dizem os cientistas. Embora a arquitetura dos LLMs atuais tenha um mecanismo de atenção, ele opera de forma diferente da atenção humana, que pode manter seletivamente o foco em uma dimensão relevante (a cor) enquanto ignora outra igualmente saliente (o significado da palavra) por longas sequências.
Artigo: Deficient executive control in transformer attention
Autores: Suketu Chandrakant Patel, Hongbin Wang, Jin Fan
Publicação: PNAS Nexus
Vol.: 5, Issue 6, pgag149
DOI: 10.1093/pnasnexus/pgag149

| Ver mais notícias sobre os temas: | |||
Concentração | Trabalho e Emprego | Educação | |
| Ver todos os temas >> | |||
Comer ovos está associado a um menor risco de doença de Alzheimer
Teste simples de senta-levanta por 30s prevê o quão bem você envelhecerá
Humanos podem regenerar tecidos e membros? Ciência diz que é muito provável
Creatina: do esporte ao cérebro, o que a ciência realmente diz sobre o suplemento
Dieta de 4 semanas pode lhe tornar biologicamente mais jovem
Cientistas revelam o melhor exercício para aliviar a dor da artrite no joelho
Composto vegetal raro contra o câncer acaba de ser decifrado
Descoberta acidental mostra DNA quebrando as regras da vida
O complexo sentido de "religião" no Japão
Medo e ansiedade ainda são úteis aos humanos? A resposta irá lhe surpreender


IA é reprovada em teste básico de atenção
Coração tem desvio natural que pode evitar cirurgias cardíacas arriscadas
Pernilongos aprendem a associar repelente de insetos a fonte de alimento
Homens ou mulheres são mais bonitos? As mulheres decidem o resultado
Seus amigos são mais cínicos do que você?
Minirrobô cirurgião 5 em 1 tem tamanho de um grão de arroz
Chip brasileiro integra múltiplos sensores para análises clínicas em alta velocidade
Suplementos de cálcio e vitamina D não previnem fraturas e quedas em idosos
Gosto de você, mas não fique tão perto
Órgãos criados em laboratório são transplantados com sucesso
Vacina do Butantan contra dengue grave tem 89% de proteção
Brasil tem primeiras mortes por febre oropouche no mundo
Censo 2022: Por que várias cidades brasileiras tiveram diminuição da população?
Brasil tem primeiro caso de gripe aviária em aves domésticas
Brasil decreta emergência zoossanitária devido à gripe aviária
Proibido o uso de animais em pesquisas de cosméticos e higiene pessoal
A informação disponível neste site é estritamente jornalística, não substituindo o parecer médico profissional. Sempre consulte o seu médico sobre qualquer assunto relativo à sua saúde e aos seus tratamentos e medicamentos.
Copyright 2006-2026 www.diariodasaude.com.br. Todos os direitos reservados para os respectivos detentores das marcas. Reprodução proibida.